双目相机立体匹配-stereo matching
[TOC]
预备知识
最近在学习CV相关的双目相机立体匹配Stereo Matching,本文是关于GwcNet的一些学习和思考。开始之前,先需要理解几个概念:视差、双目相机匹配、代价体。
RGB像素
图像由像素组成,一张 1920x1080 分辨率的屏幕就代表有1920x1080个像素。RGB代表光的三原色。R=Red,G=Green,B=Blue。这三种颜色通过不同的亮度组合可以形成各种颜色。计算机给每种颜色的亮度划分了 0 ~ 255 共 256 个等级。
可以计算出,三种原色,256种亮度,可以组合出$256^3≈1677万$中颜色。
每一个彩色图像的像素点都由红、绿、蓝三个发光的子像素(Sub-pixels,可以理解为三个微型 LED 灯)紧挨着组成的,可以看成一个三维向量:(R, G, B),比如 (255, 0, 0) 代表纯红。这是原始像素。
像素的高维特征向量
一个图像有1024个像素,理论上特征向量也有1024个,一一对应,相当于给每一个像素发一张“高维身份证”。但在工程上,使用 CNN 提取高维特征向量十分消耗显存,如果像素和特征向量 1:1 很容易爆显存。
所以要降采样 : 使用“步长卷积(Stride Convolution)”或“池化(Pooling)”将图像缩小(降采样)。比如在比如 GwcNet 中,特征图的宽和高都被缩小到了原来的 $1/4$。
假设原本像素为$32×32$,降采样1/4后得到 $8*8=64$个特征向量。此时这 64 个特征向量里的每一个,代表的不再是单个像素,而是一小块区域(感受野)的特征汇总。
视差
定义
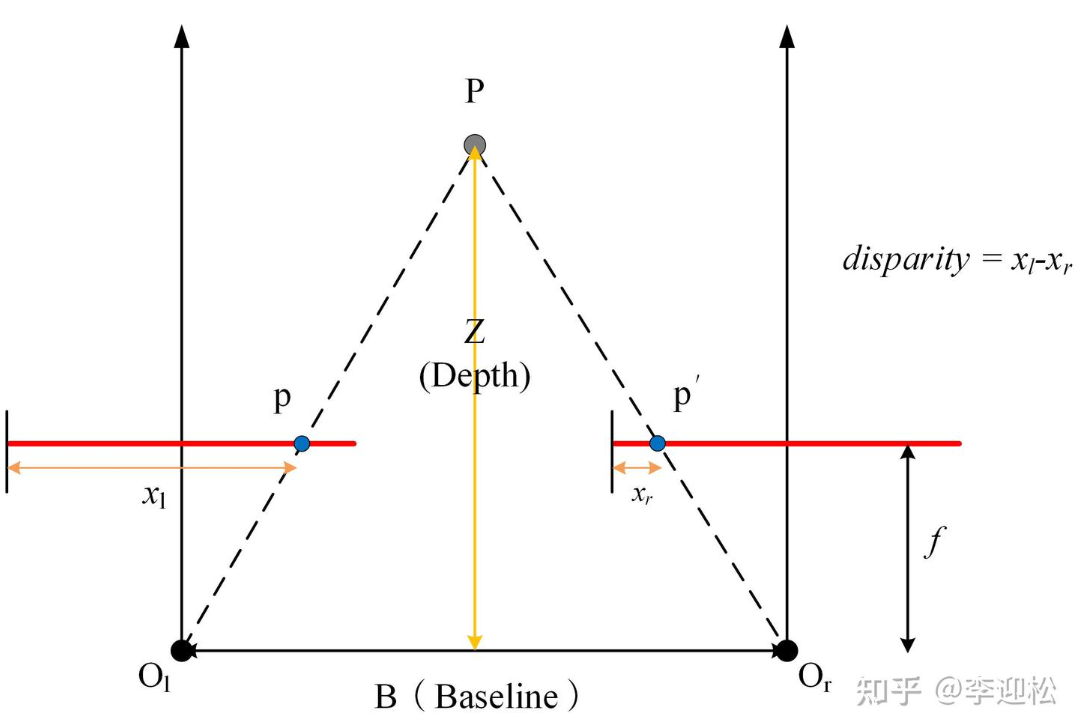
有一个理想的双目相机系统,两个相机的成像平面是共面和行对齐的,左图中某个点,与对应右图中的匹配点在同一个水平线上。
如果空间中有一个三维点 $P$,它在左图的像素坐标是 $(u_L, v)$,在右图的对应坐标是 $(u_R, v)$ (注意纵坐标 $v$ 是一样的),那么这个点的视差 $d$ 就是它们在水平方向上的坐标差:
这就是视差。它是一个标量,单位是像素(Pixel)。
应用
视差可以用来求一个像素点的深度(Depth),就是像素点对应的物体实际离相机的距离。具体公式为:
Z为深度,f为相机焦距,B为基线(左右两个相机光心之间的物理距离),d为视差
学术
当前有一些立体匹配网络,基于代价体构建的GwcNet、IGEV,基于循环迭代的RAFT-Stereo。这些网络本质都是求视差d,即为左图的一个像素点,在右图如何寻找最准确的对应点求出视差。
简而言之,视差是连接2D图像特征和3D几何物理世界的桥梁。
双目相机的匹配
核心任务
在左右两张图像中,把显示中同一个物理点的像素点找出来。(寻找同名点)
这里举一个实例
使用双目相机拍摄一个苹果。苹果的果梗在左相机,在右相机的。使用人眼很容易根据经验找出两幅图像的相同像素点。但是计算机需要一种算法,当它拿到左图果梗的像素时,能去右图里精确地“匹配”到对应的那个像素。
事先要对相机做极线校正,使双目向机成像水平,这样找一点在另一图像中像素点,只需要沿着水平方向滑动搜索。
代价体
介绍
Cost Volume,一种为了求解视差定值的数据结构,他是三维张量。
在刚才的苹果匹配例子中,实际采用的是穷举法打分:对于左图的一个像素点,在右图中把所有可能的视差偏移量(比如0~192像素)穷举一遍,每次都计算出左右两个像素块的相似度或者差异度(代价)。当这个代价最小,即两个像素块差异最小时,可以认为找到了匹配像素点。
有一些传统方法:
- 传统方法:计算两个像素快的绝对误差和 SAD
- 深度学习:提取左右图的高维特征矩阵,计算内积,相似度越高越好
把左图所有的像素 $(H \times W)$,针对所有可能的视差搜索范围 $(D)$,全部算出一个匹配得分后,把这些得分堆叠在一起,就形成了一个三维的张量(Tensor)—— 这就是代价体(Cost Volume)。
它的维度通常是:最大视差数 $(D) \times$ 图像高度 $(H) \times$ 图像宽度 $(W)$。
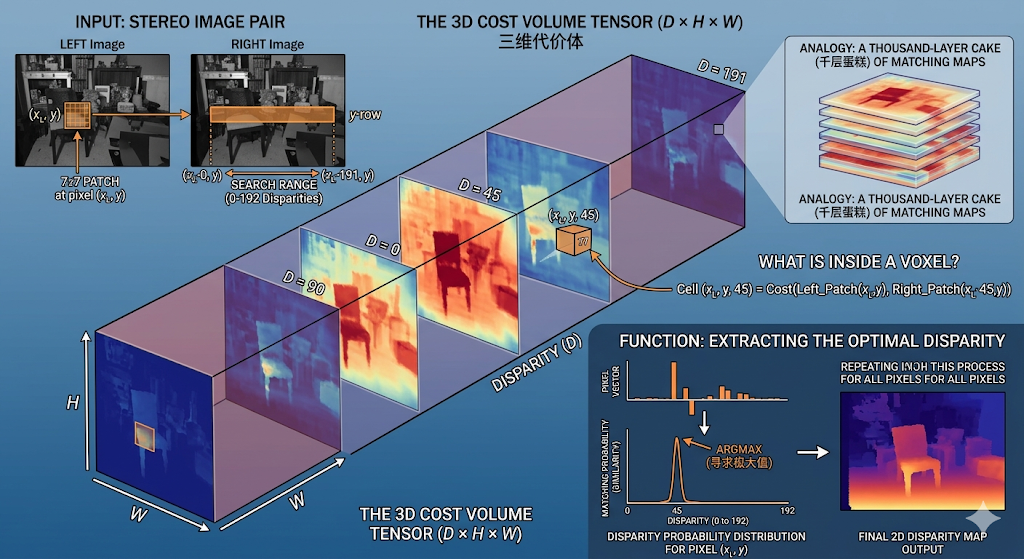
关于这个坐标D ($D$ / Disparity),被称为通道维度或深度维度,它代表了所有的候选视差值。
关于坐标$(x, y, d)$的含义,每一个坐标存放一个数值(打分),这个数值代表了:左图的坐标 $(x, y)$ 这个像素,如果去和右图的坐标 $(x-d, y)$ 这个像素匹配,它们的“差异度(Cost)”或“相似度(Correlation)”有多大。
作用
有了这个存满打分值的三维张量,即可以求视差。
如果这个数值$f(x_0, y_0, d_0)$是相似度,那么这个数值的最大值$f_m(x_0, y_0, d_0)$,对应的$(x_0, y_0, d_0)$点,这个$d_0$即为像素$(x_0, y_0)$实际视差。
为什么要把它做成一个完整的三维张量? 如果只看单个像素,很容易受噪声干扰(比如一块纯白色的墙,右图哪个位置看起来都很像)。把所有像素的匹配得分整合到一个宏大的 3D 张量中后,现代深度学习模型(比如 3D CNN 或 3D 堆叠沙漏网络)就可以在这个大张量里进行空间维度的平滑和上下文信息聚合。它可以参考周围像素的信息,把原本不明显的极值变得更加突出和准确。
求视差的基本流程
1 | graph TD |
关于这个流程
这个流程本质上是计算机在做信号搜索与解码。
Step1 RGB像素输入
系统接收到左右图,为许多RGB像素点。但不能直接使用RGB原始像素去匹配,因为左右图相同颜色的点可能不止一对,引发歧义。
Step2 特征提取
为解决歧义,使用2D CNN卷积神经网络,将原本单薄的 RGB 像素被编码成了一个高维的特征向量(比如64维度),,然后Pooling进行降采样,这个特征向量包含了一个像素点高级征信息(如是否处于边缘、材质),是他的“指纹”。
Step3 构建Cost Volume
根据特征向量,在右图的同一行寻找左图像素的对应点,假设最大视差范围是 192 个像素。系统会把左图的特征,与右图平移 0 到 192 个位置的特征分别进行比对(GwcNet 采用了分组相关,按特征子空间分别计算相似度)。
计算完毕构成了巨大的张亮 — 代价体。
像素提取特征向量,经历了降采样的步骤,这时特征向量数量小于RGB像素数量,这时是怎么根据特征向量来构建代价体的?能够根据它直接对比吗?
代价体是由“降采样”后的少量特征向量构成的
数学上比较高维向量的手段非常优雅
在CV领域,比较两个高维特征向量(比如左右图都是320维的向量)相似度,向量内积。如果两个向量相似度高,方向指向相似,那么内积值会很大。如果积出来是复数或者是0,那么关系很微弱。
Step4 代价聚合
刚建好的代价体是非常嘈杂的,使用3D卷积神经网络CNN把代价体进行精炼,使其变成干净的概率分布体。
Step5 视差回归
针对左图的某一个像素,我们沿着代价体的视差维度看过去,会得到一条平滑的概率曲线。理论上直接找最高点,即视差。但实际上要构建视差图:不直接取最高点(Argmax),而是使用 Soft-argmin 操作。它会对这条概率曲线进行加权求和(算期望值)。这样不仅能输出连续的、平滑的视差图,还能让整个网络保持“可微”状态,从而支持端到端的反向传播训练。
GwcNet
这篇论文的核心贡献在Step3,提取出图像特征后构建代价体。
GwcNet
Group-wise Correlation Stereo Network (GwcNet)
这篇论文属于双目立体匹配领域Stereo Matching,是2019CVPR的会议论文。它提出了一种构建代价体的高效方法(GwcNet),方便求解视差。
背景 - 构建代价体的两难
极端一:全相关
极端二:直接拼接
折中解法:分组相关
核心贡献
分组相关 Group Wise Correlation
该方法将左右图提取的两组特征向量,沿着维度通道channel dimension 划分成多个组。然后每一组的对应特征之间独立计算相关性。

改进的 3D 堆叠沙漏聚合网络
